




生成式AI大模型在智能對話、內容創作、編程等人機交互場景中大放異彩,各行業企業也在積極構建自己的AI模型,以支撐垂直專業領域的智能化應用,提升企業洞察力,創造業務新價值。
但AI大模型不具備長期記憶能力,在服務垂直專業領域時會存在知識深度和記憶時效性不足的問題,企業構建屬于自己的大模型面臨挑戰。
基于此現狀,柏睿數據推出LLMOps平臺、向量存儲查詢引擎兩種產品方案,助力企業高效、簡單地構建和應用完美適配業務場景的AI大模型。企業不僅能夠通過柏睿LLMOps平臺在大模型上做垂直領域的模型微調,還可通過向量存儲查詢引擎,基于企業的自有知識資產構建本地知識問答服務,使得服務更加專業、實時且智慧。
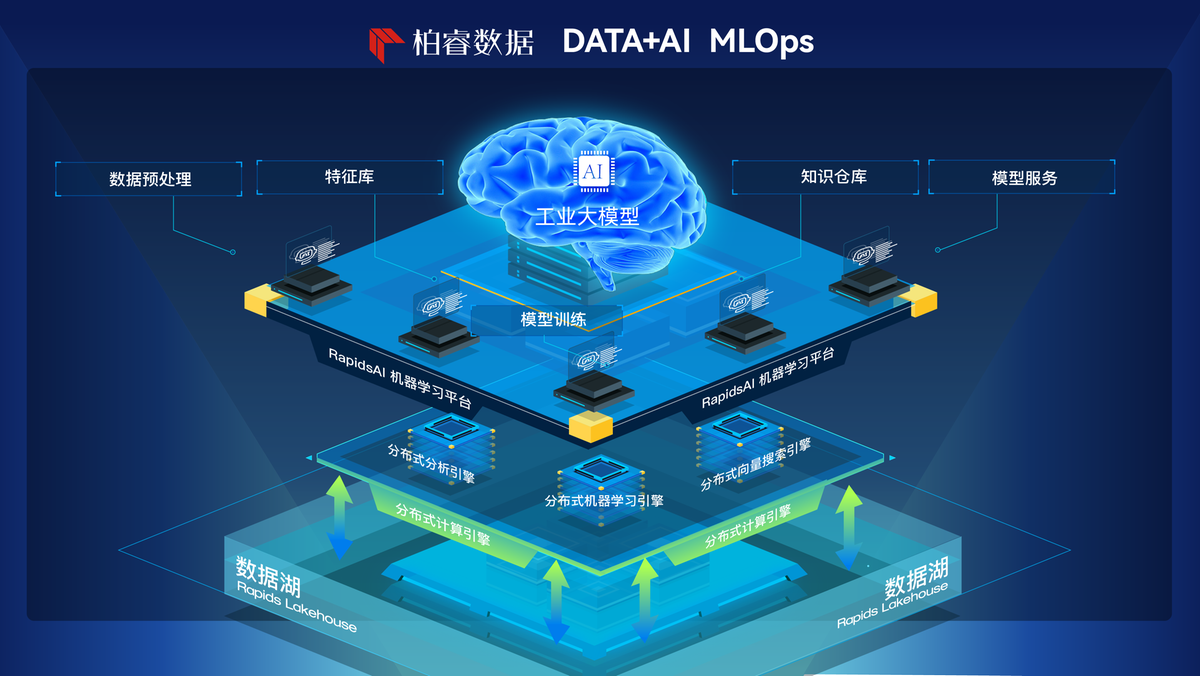
柏睿LLMOps: 高效微調大模型
LLMOps本質是人工智能研發運營體系(MLOps)的子類別。柏睿數據智能平臺Rapids AI 是一個以數據為中心、以MLOps為方法論的機器學習平臺,致力于解決 AI 生產過程中團隊協作難、管理亂、交付周期長等問題,最終實現高質量、高效率、可持續的 AI 生產過程。
在大模型時代,柏睿數據在基于Rapids AI的已有MLOps生態鏈中補充LLMOps的能力,更加關注大語言模型的構建和運行,其能力特點包括:
訓練微調模型能力。通過柏睿LLMOps平臺,通過柏睿LLMOps提供的優化的基礎架構、資源管理能力和精簡的開發流程,企業能夠在本地訓練和微調大模型,確保在模型訓練、迭代和部署過程中提高效率和控制能力,從而充分利用大模型實現人工智能賦能業務場景的變革能力。
可視化編排能力。柏睿LLMOps平臺的可視化工作流編排能力,使數據科學家和研究人員能夠結合大模型及其他應用,通過prompt工程,快速構建工作鏈,充分發揮大模型的全部潛力,實現敏捷交付。
資產管理能力。與傳統MLOps類似,LLMOps也具有數據、模型、代碼的統一管理和運維能力。對資產的版本和質量進行持續監控和高效統一管理,并加以風險防控和安全管理等手段,從而實現有效治理。
應用運維能力。通過可視化的方式編寫Prompt并調試,并自動接入上下文或數據集,只需幾分鐘即可發布AI應用。同時提供模型API服務,助力企業快速將大模型的能力集成到業務場景應用中,而無需關注復雜的后端架構和部署過程。
通過柏睿LLMOps平臺,企業可以簡化LLM支持應用程序的開發、部署和維護過程,更高效地部署好用、可靠、精準地AI大模型,加速釋放大語言模型(LLM)在垂直應用場景中的全部潛力。
柏睿向量存儲查詢引擎:強化LLM記憶的“海馬體”
但 LLM 更像是容易失憶的大腦,需要海馬體來強化記憶,向量數據庫就是支撐LLM長期記憶的“海馬體”:基于向量數據庫,一方面,LLM 通過瀏覽專用數據與知識使回答更精準;另一方面,LLM 能回憶自己過往的知識和經驗,通過“反思”為用戶提供更個性化的服務。
向量數據庫作為一種能夠存儲和處理圖片、文字、語音等多種數據類型的系統,通過embedding加工使LLM接觸和學習的數據向量化,能夠有效地支持多模態數據的存儲、索引和查詢。向量搜索通過與向量數據庫中存儲的海量向量進行相似度匹配,找到最符合要求的k個記錄,此過程可以助力LLM實現相似文本搜索、文本推薦系統、問題回答和知識檢索等功能。
柏睿數據作為一家深耕“Data + AI”技術的公司,一直致力于將AI的能力與數據庫結合,面向AI大模型時代推出向量存儲查詢引擎,支持數據的向量化存儲和向量索引。柏睿數據RapidsDB的數據聯邦機制能夠支持結構化數據和向量數據的存儲與查詢,且采用全內存分布式架構和大規模并行計算引擎,具備高性能、高可用、彈性擴展等特點,切實解決企業對向量的快速檢索需求。
基于柏睿數據的大模型訓練運維管理生產線 LLMOps及向量存儲查詢引擎,結合特定行業或應用的場景,企業可獲得匹配自身垂直領域的智能化能力。
LLM+RapidsDB:人人都是數據分析師
通過在具有完全知識產權的全內存分布式數據庫RapidsDB中引入LLM,柏睿數據推出了具有自然語言接口的分析型數據庫。用戶通過自然語言提問,可以從RapidsDB的多張數據表中快速查詢結果并返回相應分析報告,進一步降低數據庫的使用門檻,真正實現“人人都是數據分析師”。
通常,自然語言轉SQL是將數據庫中所有表的schema傳遞給大模型,大模型會根據提問和schema信息生成相應的SQL。但是,如果數據庫中存在大量的數據表,則會導致傳遞給數據的schema信息超出token的限制,從而無法完成自然語言轉SQL的任務。
針對該問題,柏睿數據首先將數據庫中的schema通過embedding轉為向量,并存放于向量數據庫;再計算問題和schema 向量的相似度,選擇與問題匹配的表信息,將篩選后的schema傳遞給大模型,從而大大減少了單次prompt的token消耗。這樣一方面解決了數據表過多無法生成SQL的問題,一方面減少了token數,降低大模型的使用成本。
同時,為讓大模型生成更準確的SQL,柏睿數據也在本地利用LLMOps對大模型進行微調,強化大模型對中文的理解和輸出,并通過SQL語料的微調,提高SQL生成的準確率。
行業大模型應用:物聯網下的智慧工廠
在工廠設備全生命周期管理中,各個環節都會采集、匯聚海量結構化和非結構化的數據、實時流數據和歷史數據等多種類型的數據,并需要從這些海量數據中高效、實時地獲取能夠為業務人員所用的有效信息。
柏睿數據智慧工廠解決方案通過將大語言模型與物聯網技術相結合,賦能工廠智能運維場景,重塑數據追蹤和分析流程,助力工業企業獲得更深入的洞察和智能決策,提高生產質效、降低成本。
首先,采集工廠設備大數據,包括建立設備靜態、動態統一的數據庫以及設備管理全業務環節的日常業務數據庫。
其次,建立“引發工況的可能問題”的樣例庫。分析不同類型設備出現的不同故障表現及原因并采取適當行為解決該故障,由此形成故障體系。
再次,通過建立專家知識庫配置平臺,將行業專家的知識整理后錄入知識庫,作為工廠故障診斷分析、優化運行的指導依據。
最終,一方面將知識庫的內容向量化存儲到向量數據庫中,與LLM結合,輸出應對故障和優化問題的、基于經驗的回答;另一方面,使用積累的數據對LLM進行微調,使得系統在每次處理和分析數據的過程中都能夠通過持續的數據庫運算進行“學習”。
由此,大數據平臺從工廠運營的經驗中收集新的故障檢修信息,通過自動學習架構捕捉獲得的經驗進行編譯后,再提供給所有使用者。
未來,柏睿數據將持續發力“Data + AI”的前沿技術與應用,與客戶、伙伴攜手同行,助力AI大模型深入關鍵行業的垂直場景,共同構筑數字化全域能力,共同推動產業數智化發展,共同建設智能美好未來!










 掃碼下載
掃碼下載 中文網微信
中文網微信